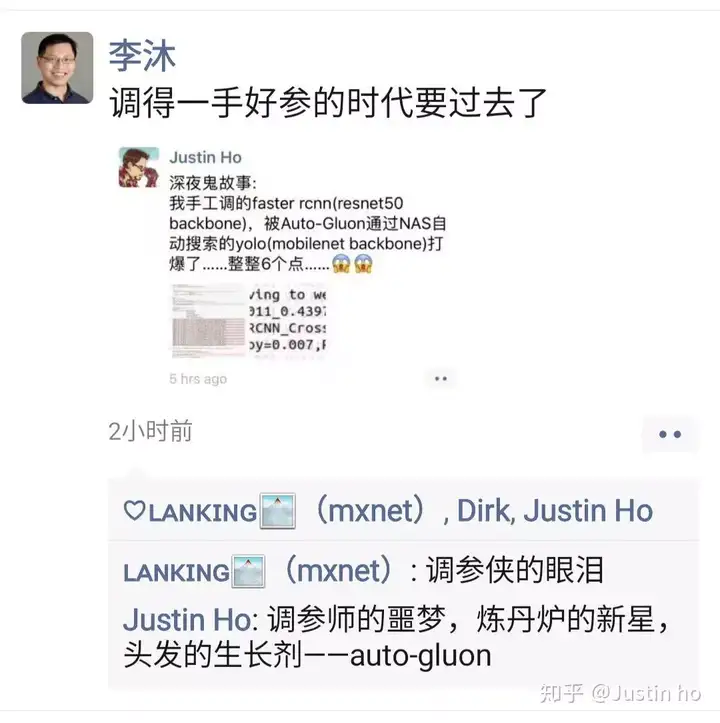
自动化机器学习之Autogluon的安装(windows版)
- Autogluon简介
Autogluon 是由阿里巴巴集团开源的一款自动化机器学习工具库,它基于 Apache MXNet 构建。Autogluon 的目标是提供一种简单且高效的方式来解决机器学习问题,特别是对于那些没有深厚机器学习背景的用户。它通过自动化处理数据预处理、特征工程、模型选择、超参数调整等步骤,使得机器学习模型的训练和应用变得更加容易和高效。
-主要用途
-
1.自动化模型选择:Autogluon 可以自动选择最适合当前数据集的机器学习模型,包括传统的机器学习模型和深度学习模型。
-
2.自动化特征工程:它能够自动识别和生成有用的特征,以提高模型的性能
-
3.超参数优化:Autogluon 可以自动调整模型的超参数,以获得最佳的性能
-
4.集成学习:它支持集成学习,可以将多个模型的预测结果进行融合,以提高预测的准确性和稳定性
-
5.并行计算:Autogluon 支持并行计算,可以利用多核处理器或分布式计算环境加速模型训练
-
6.易于使用:Autogluon 提供了简单的 API 和命令行界面,使得用户可以轻松地使用它来解决机器学习问题
下面教大家怎么安装
可以使用conda安装的管理python环境
这里使用极简版miniconda3:(附下载地址与下载注意事项)
https://blog.csdn.net/weixin_43828245/article/details/124768518
建议下载3.7-3.9版本miniconda3-python,否则会导致后续出错 (亲身经历😭)
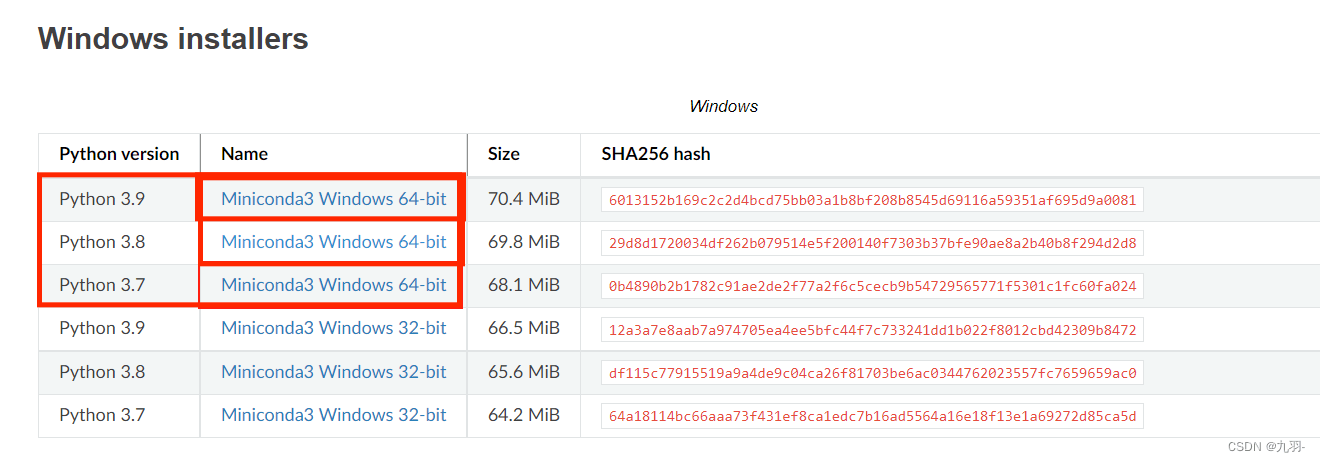
如果本身就有miniconda3不过python-version不是3.7-3.9也可以用命令conda create -n py39_env python=3.9等来创建环境
-
步骤1--搭建Pytorch_CPU(可选)
1.在anaconda里输入命令命令如下,这里使用的Python的版本为3.9:
conda create -n PyTorch_cpu python=3.9构建好虚拟环境后通过命令conda activate Pytorch_cpu来进入该虚拟环境:
conda activate Pytorch_cpu搭建cpu加速,方便后续下载
2.Pytorch_CPU安装和配置
下面我们进入到PyTorch的官网:https://pytorch.org/
点击Get Started,进入后按照如下选择(只针对windows系统、pip安装、Python版本、无GPU的情况,如有其它需要则应该选择相应的
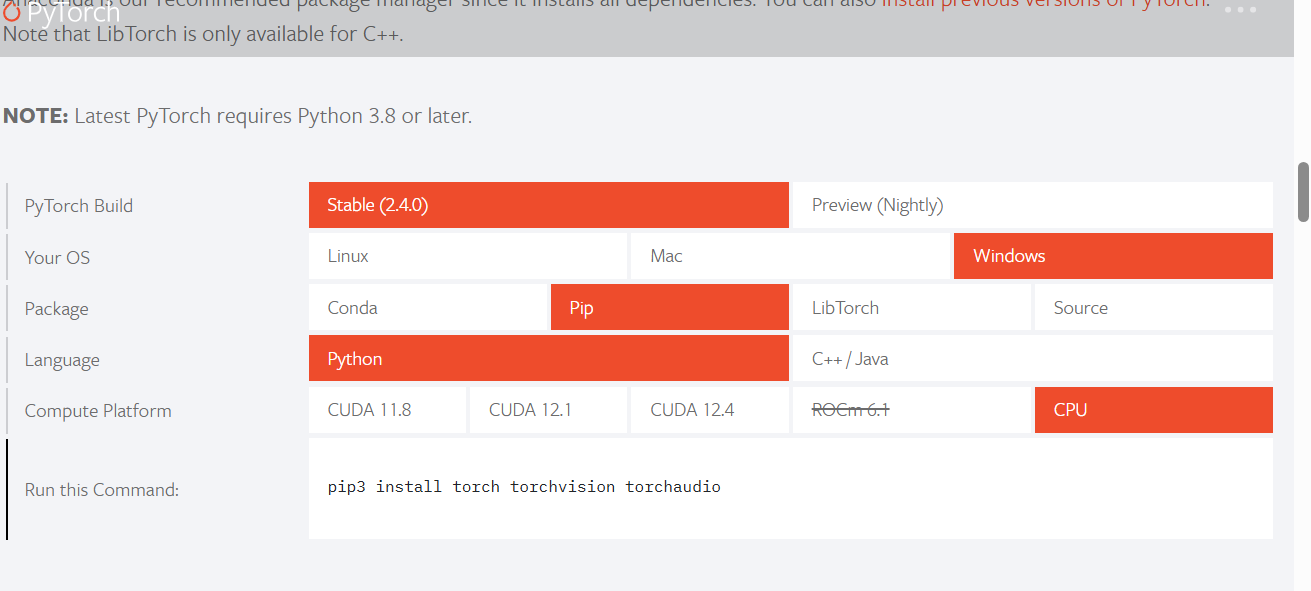
下面已经自动生成了一句安装PyTorch和torchvision的命令,查看一下版本无误的话就复制这条命令并粘贴到prompt命令窗口中:
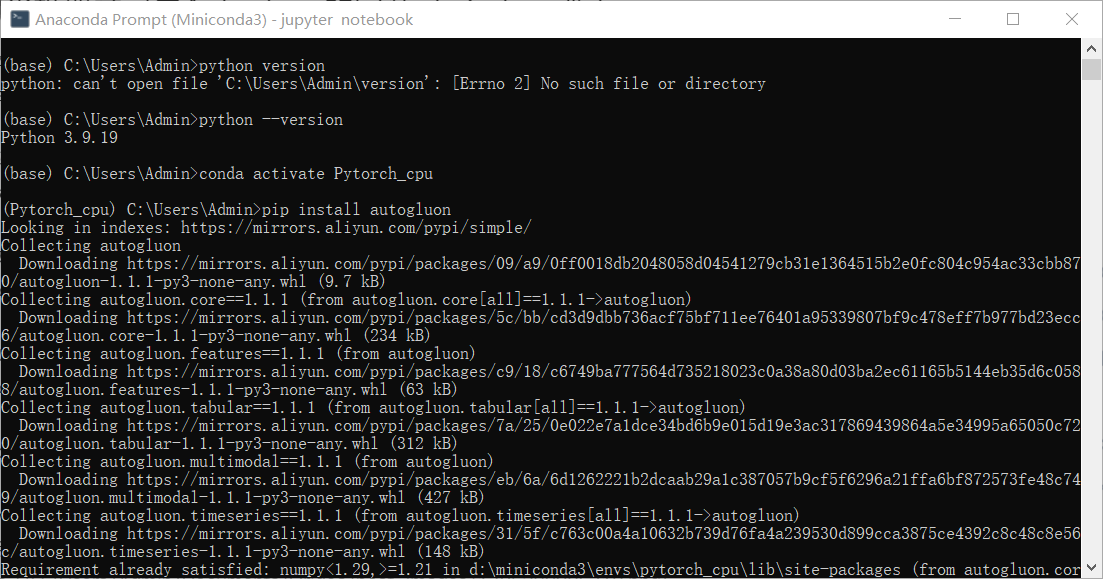
这边是已经安装过了所以没有下载安装的过程,第一次安装会需要下载并安装,过程可能会很慢,这里建议换成国内的镜像源的快速度会得到飞速的提升。以上如果没有问题的话则已经安装好了cpu版的PyTorch,这时我们可以测试一下是否安装正确:
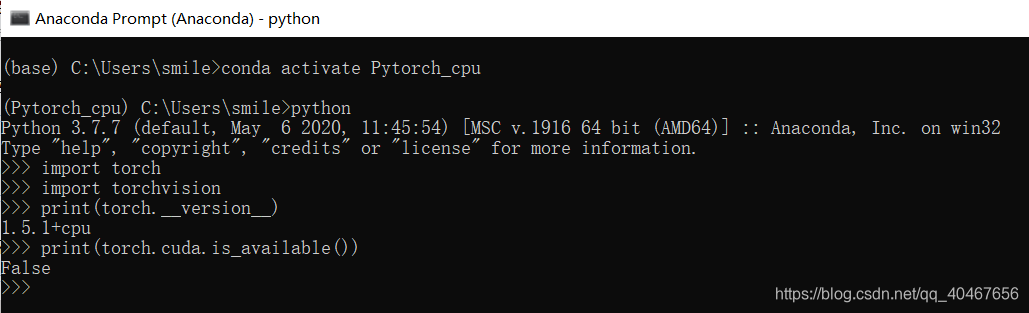
最后我们较好使用PyTorch的IDE是pycharm,所以还需要在pycharm上设置一下解释器:
这一步留给自己探索吧(其实是懒了)
附上可能用到的教程:https://blog.csdn.net/qq_38473254/article/details/132302229 -
步骤2--安装Autogluon(必须)
在anaconda里面输入命令即可:pip install autogluon
如果前面安装了pytorch_CPU,可以选择加速节省下载时间,命令如下:conda activate Pytorch_cpu
估计要下载几分钟左右....
安装完成的界面:
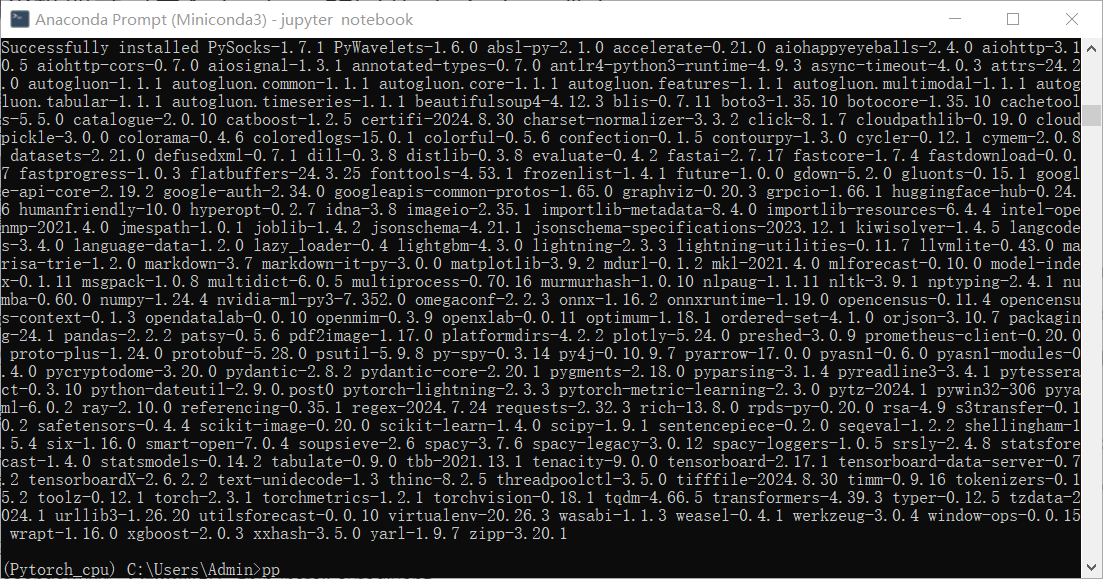
-
步骤3--安装Jupter(必须)
命令:pip install jupyter -
步骤4--运行Jupter notebook(必须)
命令:jupyter notebook
之后会弹出网页
我们在官网上随便找个例子运行一下:
from autogluon.tabular import TabularDataset, TabularPredictordata_root = 'https://autogluon.s3.amazonaws.com/datasets/Inc/'
train_data = TabularDataset(data_root + 'train.csv')
test_data = TabularDataset(data_root + 'test.csv')predictor = TabularPredictor(label='class').fit(train_data=train_data)
predictions = predictor.predict(test_data)
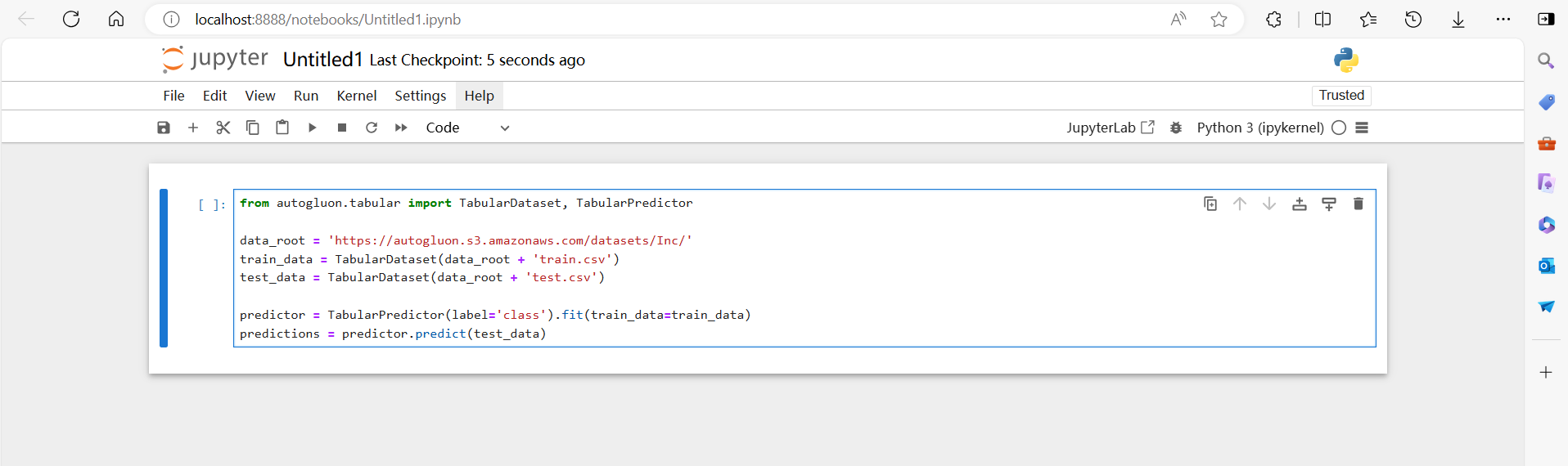
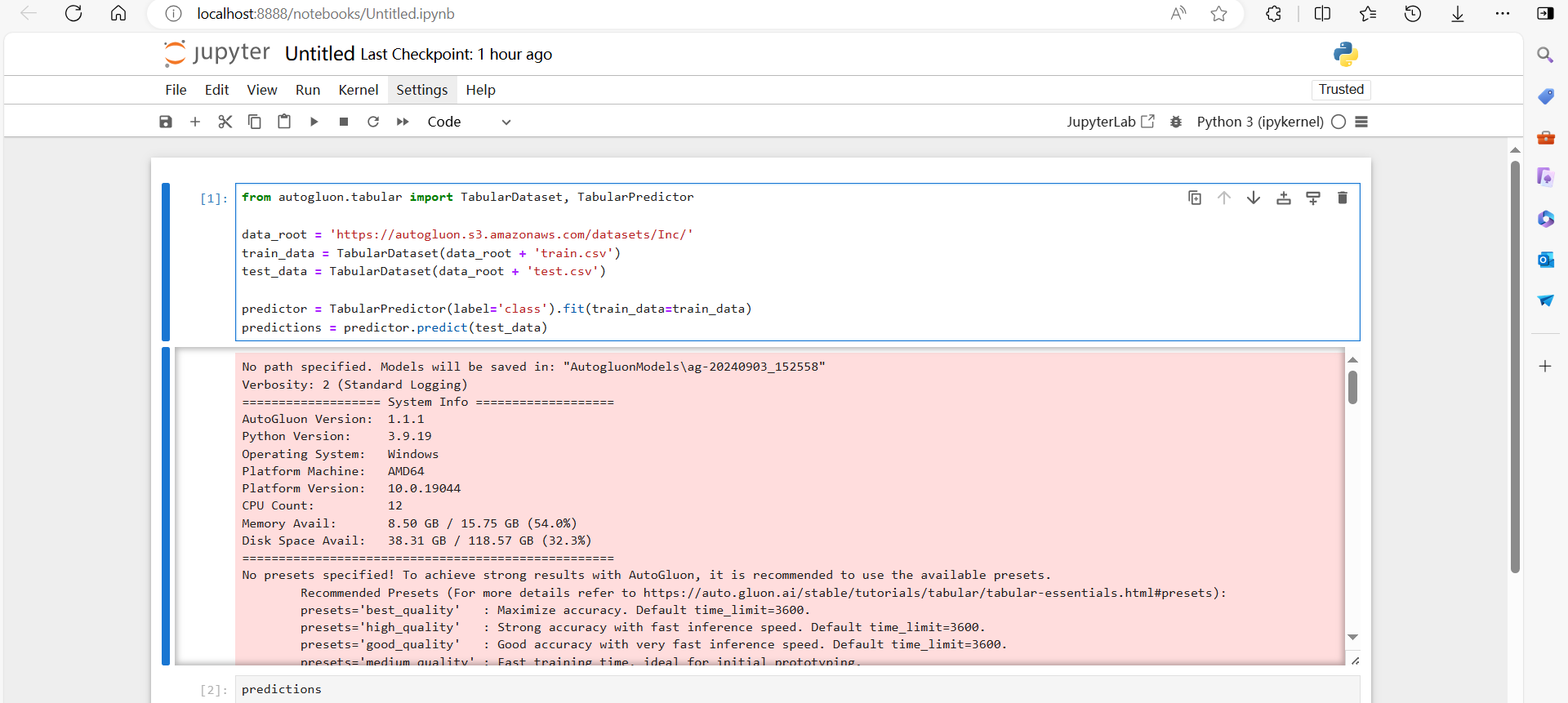
这样,就完成了基本操作,接下来的东西以后再讲吧~😉